

Scalable, multi-source ingestion pipelines built for speed and reliability.
Hanas enables real-time and batch ingestion from diverse data sources: relational databases, APIs, file systems, message queues, and cloud services. Our ingestion layer is designed for operational resilience, schema management, and integration with downstream processing.
Key Features:
🔹 Connectors: DBs, APIs, flat files, Kafka, cloud buckets
🔹 Real-time & batch scheduling
🔹 Schema registry & schema evolution
🔹 Validation, retry, monitoring dashboard
Flexible data transformation engine combining code, logic & reusability.
Clean, enrich, and reshape raw data into analysis-ready datasets using SQL, Python, or visual workflows. Hanas supports both technical and business-defined logic, enabling centralized, versioned, and testable transformation pipelines.
Key Features:
🔹 Integration with dbt, PySpark, Airflow
🔹 Business rules & lookup enrichment
🔹 Data quality checks & profiling
🔹 Reusable ELT jobs with parameterization
Unified governance framework with structured metadata, standardized data models, and secure access control.
Our platform provides end-to-end visibility and control over data assets — from metadata management and data lineage to standardized data modeling and role-based governance. By enforcing consistent definitions, ownership, and usage policies, we help organizations ensure compliance, enable cross-functional collaboration, and accelerate data-driven decision-making.
Key Features:
🔹 Centralized metadata catalog and tagging
🔹 Standardized data modeling for consistency and reusability
🔹 End-to-end lineage tracking and impact analysis
🔹 Role-based access policies and data usage control
🔹 Business glossary, data ownership, and stewardship workflows
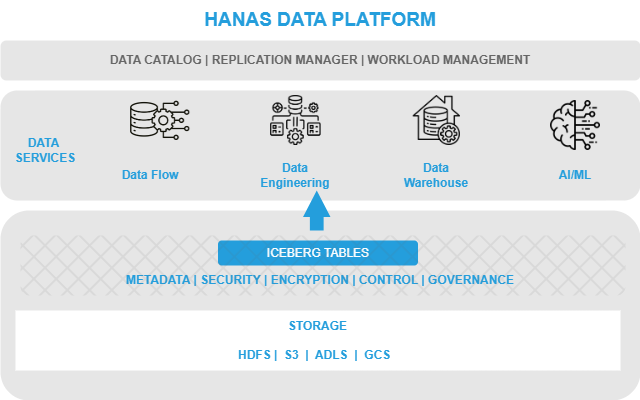
Unified, performant storage layer based on modern open data formats.
Store structured and unstructured data in one scalable platform using Iceberg or Delta Lake. Enable transactional writes, time travel, schema evolution, and fast reads — optimized for both BI and AI workloads.
Key Features:
🔹 Apache Iceberg table formats
🔹 ACID transactions & snapshot isolation
🔹 Versioning, partitioning, schema evolution
🔹 Object storage (S3, MinIO) or HDFS support
Enable intelligent access and action across all users and systems.
Hanas empowers users with secure, role-based access to curated datasets — whether for BI dashboards, ad-hoc exploration, or feeding AI/ML pipelines. Built-in support for GenAI agents accelerates insights and automates data interactions.
Key Features:
🔹 BI tool integration (Superset, Power BI, Tableau)
🔹 GenAI assistants for query, glossary, insight
🔹 Semantic layers & data masking
🔹 ML-ready output for notebooks, pipelines












Unlock the power of data to drive innovation and transform your business. Contact us today to unleash your data's potential.